Table of Contents
Origins
Over half a year ago (in April, to be exact), I eventually decided to learn Rust for good. My previous attempt during the 2022 AoC had failed rather quickly, after a few days of completing the exercises - I finally realized that I needed a real project to work on. For the last few years, I've been dealing with the different kinds of distributed systems (mostly using C#), including the typical microservices architecture or Web3. Regardless of their nature, some sort of the messaging between the independent components was always required. I had a chance to use the tools such as RabbitMQ, ZeroMQ, Kafka or Aeron (just to name a few), as well as implementing the low-level peer-to-peer communication protocols.
After a few months of trying to figure out (or just staying in the limbo I guess), what would be the best project to work on, I decided to build the message streaming platform (keep in mind that streaming is not the same as regular message broker). The other reason (besides getting to know Rust) was to truly understand the internals of the messaging systems and the trade-offs that were made by their developers - some of them being the sole implication of the theory of distributed systems (ordering, consistency, partitioning etc.), while others the result of the implementation details (programming language, OS, hardware and so on).
And this is how the Iggy.rs was born. The name is an abbreviation of the Italian Greyhound (yes, I own two of them), small yet extremely fast dogs, the best in their class.

Therefore, what I want, or actually what we want (since there's a few of us working on it already) for Iggy.rs to be - the best message streaming platform in its class. Lightweight in terms of the resource consumption, fast (and predictable) when it comes to the throughput and latency, and easy to use when speaking of its API, SDK and configuration of the project.
Project
At the very beginning, Iggy had rather limited functionality, and everything was handled using the QUIC protocol based on Quinn library. You could connect multiple applications into the server, and start exchanging the messages between them, simply by appending the data to the stream (from the producer perspective), and fetching the records on the consumer side, by providing an offset (numeric value specifying from which element in the stream, you'd like to query the data) - that's pretty much the very basics of how the message streaming platform works in terms of the underlying infrastructure.
After spending a few weeks on building the initial version, and then another few weeks on rewriting its core part (yes, prototyping + validation repeated in a continuous loop worked quite well), I managed to implement the persistent streaming server being capable of parallel writes/reads to/from independent streams supporting many distinct apps connected into it. Simply put, one could easily have many applications, and even thousands of the streams (depending on how do you decide to split your data between them e.g. one stream for user related events, another one for the payments events etc.) and start producing & consuming the messages without interfering to each other.
On top of this, the support for TCP and HTTP protocols have been added. Under the hood, the typical architecture of streams, consisting of the topics being split into the partitions, which eventually operate on a raw file data using so-called segments has been implemented as well.

It was one of the "aha" moments, when reimplementing the parallel access to the data with the usage of underlying synchronization mechanism (RwLock etc.), optimized data structures e.g. for dealing with bytes, along with the Tokio work stealing approach, yielded the great improvements for the overall throughput.
I do believe, that somewhere at this point I had realized, that Iggy might actually become something useful - not just a toy project, to be abandoned after reaching its initial goal (which was sort of already achieved).
let polled_messages = client.poll_messages(&PollMessages {
stream_id: Identifier::numeric(1)?,
topic_id: Identifier::named("orders")?,
consumer: Consumer::group(Identifier::named("payments")?),
partition_id: None,
strategy: PollingStrategy::offset(0),
count: 10,
auto_commit: true,
}).await?;
After running some benchmarks (yes, we have a dedicated app for the benchmarking purposes) and seeing the promising numbers (range of 2-6 GB/s for both, writes & reads when processing millions of messages), I eventually decided to give it a long-term shot. Being fully aware that there's still lots to be done (speaking of many months, or even years), I couldn't be more happy to find out that there's also someone else out there, who would like to contribute to the project and become a part of the team.
Team
At the time of writing this post, Iggy consists of around 10 members contributing to its different parts. Some of us do work on the core streaming server, while the other ones are focused on SDKs for the different programming languages or tooling such as Web UI or CLI - all these projects are equally important, as they add up to the overall ecosystem. But how do you actually gather a team of open source contributors, who are willing to spend their free time working on it?
Well, I wish I had an answer to that question - honestly, in case of Iggy I wasn't actually looking for anyone, as I didn't think this could be an interesting project to work on (except for myself). Then how did that happen anyway? There were only 2 things in common - all the people that joined the project were part of the same Discord communities, yet more importantly they all shared the passion for programming, and I'm not talking about Rust language specifically. From junior to senior, from embedded to front-end developers - regardless of the years of experience and current occupation, everyone has found a way to implement something meaningful.
For example, when I asked one guy what was the reason behind building an SDK in Go, the reply was the need of playing with and learning a new language. Why C# SDK? Well, the other guy wanted to dive more into the low-level concepts and decided to squeeze out great performance from the managed runtime. Why build Web UI in Svelte? At work, I mostly use React, and I wanted to learn a new framework - another member said.
My point is - as long as you believe in what you're building, and you're consistent about it (it was one of the main reasons why I've been contributing to Iggy every day since its inception, and still doing so), there's a chance that someone out there will notice it and happily join you in your efforts. Lead by example, or whatever you call it.
At the same time, we've started receiving the first, external contributions from all around the world - whether talking about simpler tasks, or the more sophisticated ones, requiring significant amount of time being spent on both, the implementation and the discussions to eventually deliver the code.
It gave us even more confidence, that there are other people (outside our internal bubble), who find this project to be interesting and worth spending their time. And without all these amazing contributors, it'd be much harder (or even impossible) to deliver so many features.
Features
At first, let me just point out some of the properties and features that are part of the core streaming server:
- Highly performant, persistent append-only log for the message streaming
- Very high throughput for both writes and reads
- Low latency and predictable resource usage thanks to the Rust compiled language (no GC)
- Users authentication and authorization with granular permissions and PAT (Personal Access Tokens)
- Support for multiple streams, topics and partitions
- Support for multiple transport protocols (QUIC, TCP, HTTP)
- Fully operational RESTful API which can be optionally enabled
- Available client SDK in multiple languages
- Works directly with the binary data (lack of enforced schema and serialization/deserialization)
- Configurable server features (e.g. caching, segment size, data flush interval, transport protocols etc.)
- Possibility of storing the consumer offsets on the server
- Multiple ways of polling the messages:
- By offset (using the indexes)
- By timestamp (using the time indexes)
- First/Last N messages
- Next N messages for the specific consumer
- Possibility of auto committing the offset (e.g. to achieve at-most-once delivery)
- Consumer groups providing the message ordering and horizontal scaling across the connected clients
- Message expiry with auto deletion based on the configurable retention policy
- Additional features such as server side message deduplication
- TLS support for all transport protocols (TCP, QUIC, HTTPS)
- Optional server-side as well as client-side data encryption using AES-256-GCM
- Optional metadata support in the form of message headers
- Built-in CLI to manage the streaming server
- Built-in benchmarking app to test the performance
- Single binary deployment (no external dependencies)
- Running as a single node (no cluster support yet)
And as already mentioned, we've been working on SDKs for the multiple programming languages:
Please keep in mind, though, that some of them e.g. for Rust or C# are more up to date with the recent server changes, while the other ones might still need to do some catching up with the latest features. However, given the amount of available methods on the server's API and the underlying TCP/UDP stack with custom serialization to be implemented from the scratch (except for HTTP transport, that's the easier one), I'd say we're doing quite ok, and I can't stress enough how grateful I am to all the contributors for their huge amount of work!
But wait, there's even more - what would be a message streaming platform without some additional tooling for managing it? We've also been developing the CLI.
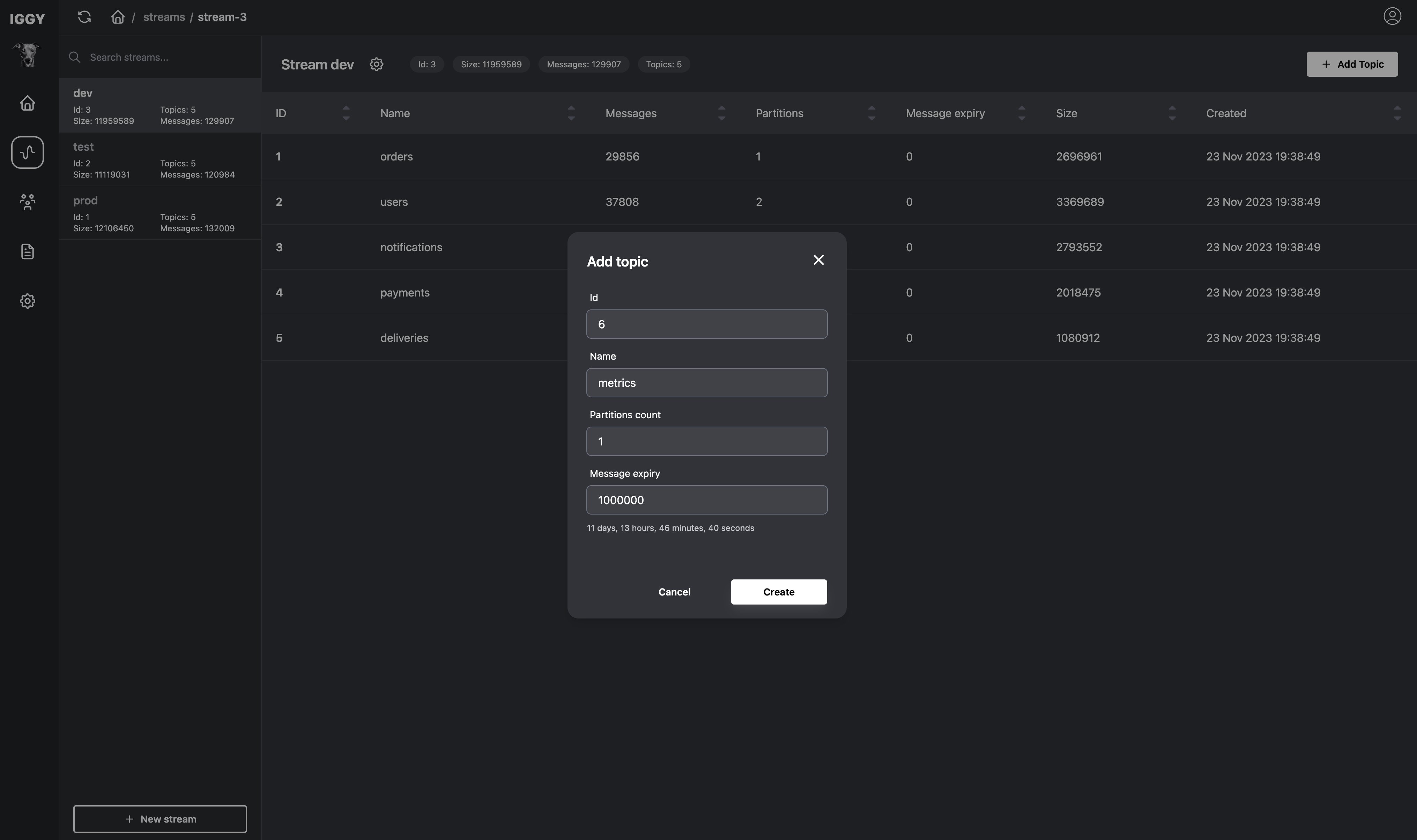
As well as modern Web UI to make it happen :)
Last but not least, we've got a fully-featured CI/CD pipeline responsible for running all the checks and tests on multiple platforms, and finally producing the release artifacts and Docker images.
At first glance, it might look like there's plenty of features already in place, but for anyone who has ever worked with the message streaming infrastructure before, that might be just a tip of an iceberg, thus let's discuss the roadmap.
Roadmap
After gaining some traction a few months ago (mostly due to landing on the GitHub trending page in July), we've talked to some users potentially interested in making Iggy part of their infrastructure (there's even one company using it already), and discussed what features would be a good addition to the current stack.
Considering what's already there, being worked on or planned for the future releases, such as interactive CLI, modern Web UI, optional data compression and archivization, plugin support or multiple SDKs, there are at least three additonal challenges to overcome:
Clustering - the possibility of having a highly available and fault tolerant distributed message streaming platform in a production environment, is typically one of the most important aspects when considering the particular tool. While it wouldn't be too difficult to implement the extension (think of a simple proxy/load balancer), allowing to monitor and deliver the data either to the primary or secondary replica (treated as a fallback server) and switch between them when one of the nodes goes down, such a solution would still result in SPOF and wouldn't really scale. Instead, we've started experimenting with Raft consensus mechanism (de facto the industry standard) in a dedicated repository, which should allow us in delivering the truly fault tolerant, distributed infrastructure with an additional data replication at the partition level (so-called unit of parallelization).
Low-level I/O - although the current results (based on the benchmarking tool measuring the throughput etc.) are satisfying, we strongly believe that there's still (potentially a huge) room for improvement. We're planning to use io_uring for all I/O operations (disk or network related). The brand new, completion based API (available in the recent Linux kernels) shows a significant boost when compared to the existing solutions such as epoll or kqueue - at the end of the day, the streaming server at its core is all about writing & reading data to/from disk and sending it via the network buffer. We've decided to give a try monoio runtime, as it seems to be the most performant one. Going further, we'd like to incorporate techniques such as zero-copy, kernel bypass and all the other goodies e.g. from DPDK or other relevant frameworks.
Thread-per-core - in order to avoid the rather costly context switches due to the usage of synchronization mechanism when accessing the data from the different threads (e.g. via Tokio's work stealing mechanism), we're planning to explore (or actually, already doing it, in the previously mentioned repository for clustering sandbox) thread-per-core architecture, once again, delivered as part of monoio runtime. The overall idea can be described in two words - share nothing (or as little as possible). For example, the streams could be tied to the particular CPU cores, resulting in no additional overhead (via Mutexes, RwLocks etc.) when writing or reading the data. As good as it might sound, there are always some tradeoffs - what if some specific streams are more frequently accessed than the others? Would the remaining cores remain idle instead of doing something useful? On the other hand, tools such as ScyllaDB or Redpanda seem to be leveraging this model quite effectively (both are using the same Seastar framework). We will be looking for the answers, before deciding which approach (thread-per-core or work stealing) suits Iggy better in the future.
Future
Why building another message streaming then? A few months ago, I would probably answer - strictly for fun. Yet, after exploring more in-depth the status quo, what we would like to achieve is sort of twofold - on one hand, it'd be great to deliver the general-purpose tool, such as Kafka. On the other hand, why not to try and really push hard the OS and hardware to its limits when speaking of the performance, reliability, throughput and latency, something what e.g. Aeron does? And what if we could put this all together into the easy-to-use, unified platform, supporting the most popular programming languages, with the addition of modern CLI and Web UI for managing it?
Only the time will tell, but we're already excited enough to challenge ourselves. We'd love to hear your thoughts, ideas and feedback - anything that will help us in building the best message streaming platform in Rust that you will enjoy using! Feel free to join our Discord community and let us know what do you think :)
P.S.
This blog uses Rust.