Table of Contents
- Throwback
- Community
- Changelog
- Tooling
- Early adopters
- Clustering & replication
- io_uring & thread-per-core + share-nothing
- Production readiness
Throwback
It's been a little over a year, since the Iggy.rs was born. The initial idea of building a side project (as a way of studying Rust) — an infrastructure for the message streaming (think of Kafka, RedPanda, Aeron etc.) — eventually turned out to be something much bigger that I could've ever imagined. In the previous post (from almost half a year ago), I did describe what's Iggy.rs all about, how it started, what's the ecosystem around it, what our goals are etc.
This particular article turned out to be a sort of catalyst, as it received a really nice traction on Reddit, and was also mentioned on the main site of Hacker News, which I do believe were the two main reasons for the growing interest & community since then. At this point, I'd like to thank you all very much for such a kind feedback — honestly, during the very first weeks of 2024, there were so many things happening on our Discord, that with the rest of the team, we sometimes had a feeling as if we were providing enterprise premium support — really cool stuff!
And although it may seem as if the project development has recently slowed down a bit, I'd say it's quite the opposite — let me quickly summary, what we've achieved so far during the last few months and what we're focusing on now, as the future looks bright :)
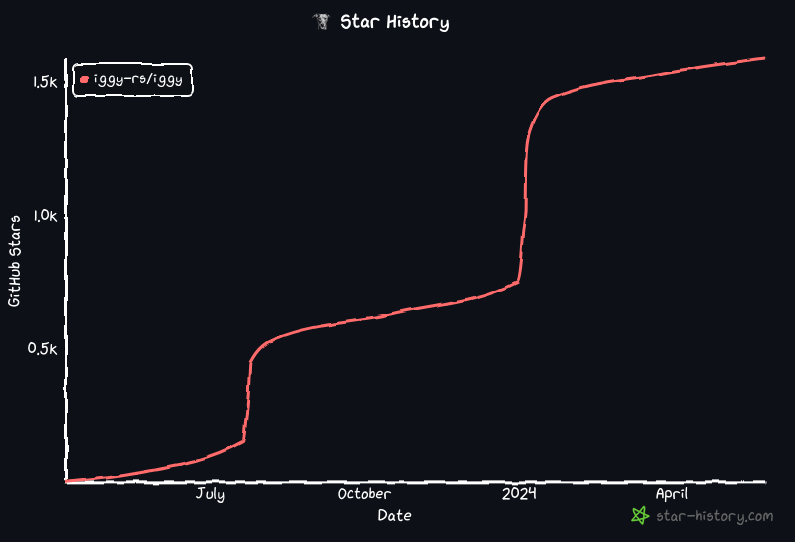
Community
First and foremost, if it weren't for the community, we wouldn't have seen such an enormous growth of the Iggy's ecosystem — we've received the dozens of pull requests and there's ~250 members on our Discord. Whether we talk about bug fixes, improvements, new features, or just sharing the experiences and discussing potential ideas — it's all equally important.
And it's been even more than that — we've seen our community members take on building the new SDKs in their favorite programming languages, fully on their own. Today, you can find the following list of supported SDKs for Iggy.rs — some of them could be lagging behind, but it's expected, as the project is still evolving, and it's not an easy task, to come up with a great development experience from the very beginning.
Changelog
Adding the brand new SDKs wasn't the only great thing that has happened during last few months. We've also made quite a lot of improvements for the streaming server itself:
- Increased the streaming server throughput by over 30% for both writes and reads
- Added messages compression for client-side & server-side supporting the different algorithms
- Implemented a new way of message batching with an additional tooling for data migration
- Fixed the possible server-side deadlock that could happen for a specific configuration
- Fixed issues with possible memory leaks when storing too many indices in memory
- Rebuilt our custom benchmarking tool
- Improved TCP connection handling
- Constantly upgrading our CI/CD with lots of testing, different runtimes, artifacts, crates and Docker images releases
- Refactored the existing Rust client SDK to follow the new conventions (without the breaking changes to the previous one)
And at the same time, we've been experimenting a lot with some fancy stuff, which you can read about in the last paragraphs :)

Tooling
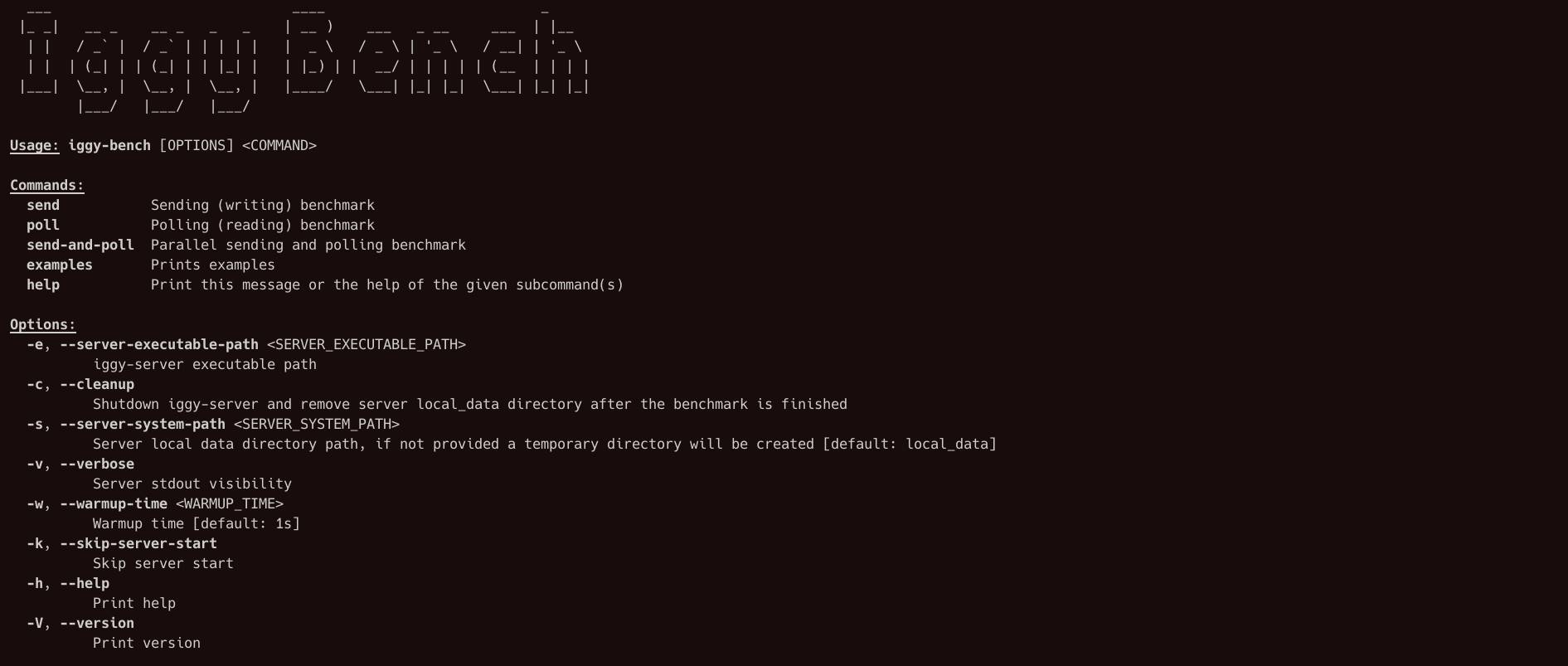
The core message streaming server and multiple SDKs might sound as the most important parts of the whole ecosystem, but let's not forget about the management tools. How to quickly connect to the the server, create new topics, validate if the messages are being sent correctly, change the user permissions or check the node statistics?
This is where our CLI and Web UI come in handy. If you're a fan of working with the terminal and used to the great developer experience, you'll find our CLI a joy to work with.
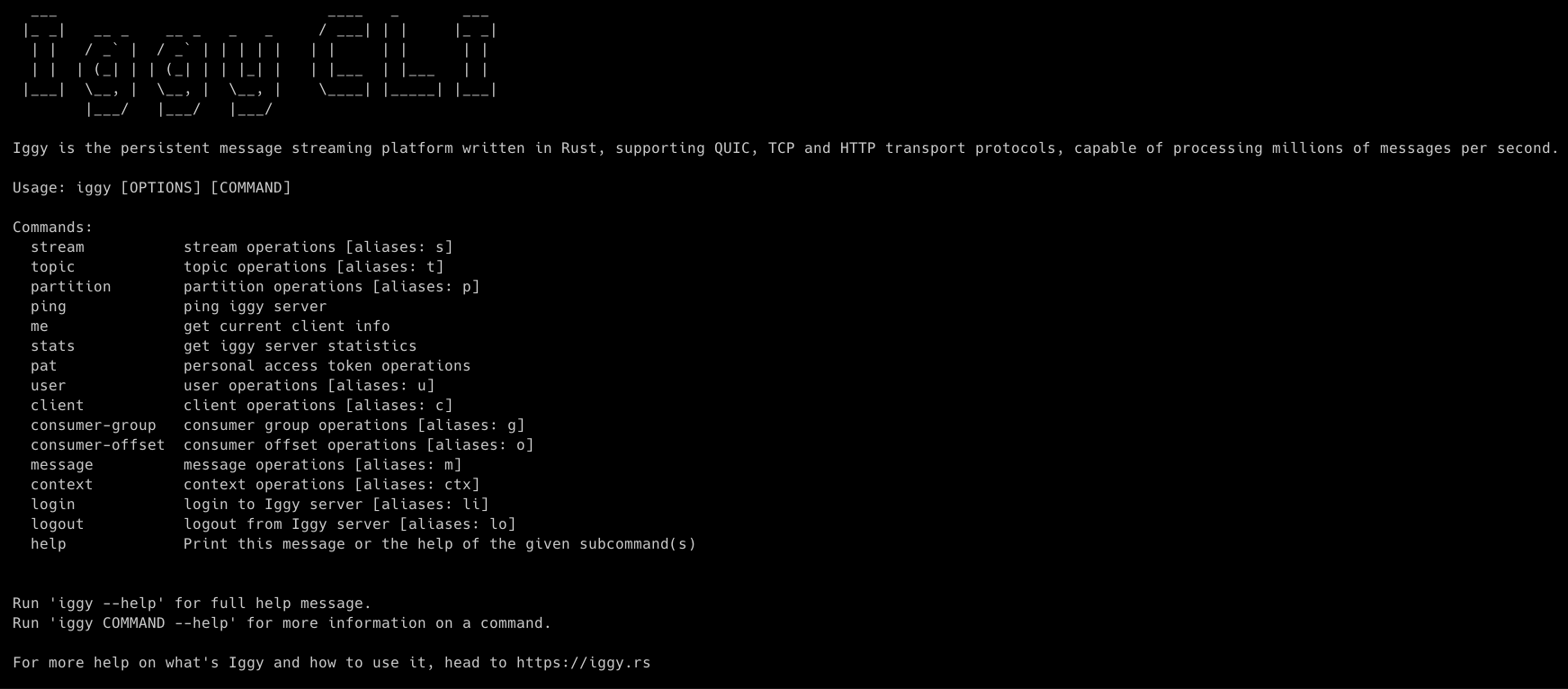
On the other hand, if you prefer a graphical interface accessible via your browser, Web UI has got you covered. What's even more impressive, is that both of these tools have been developed by the single developers.
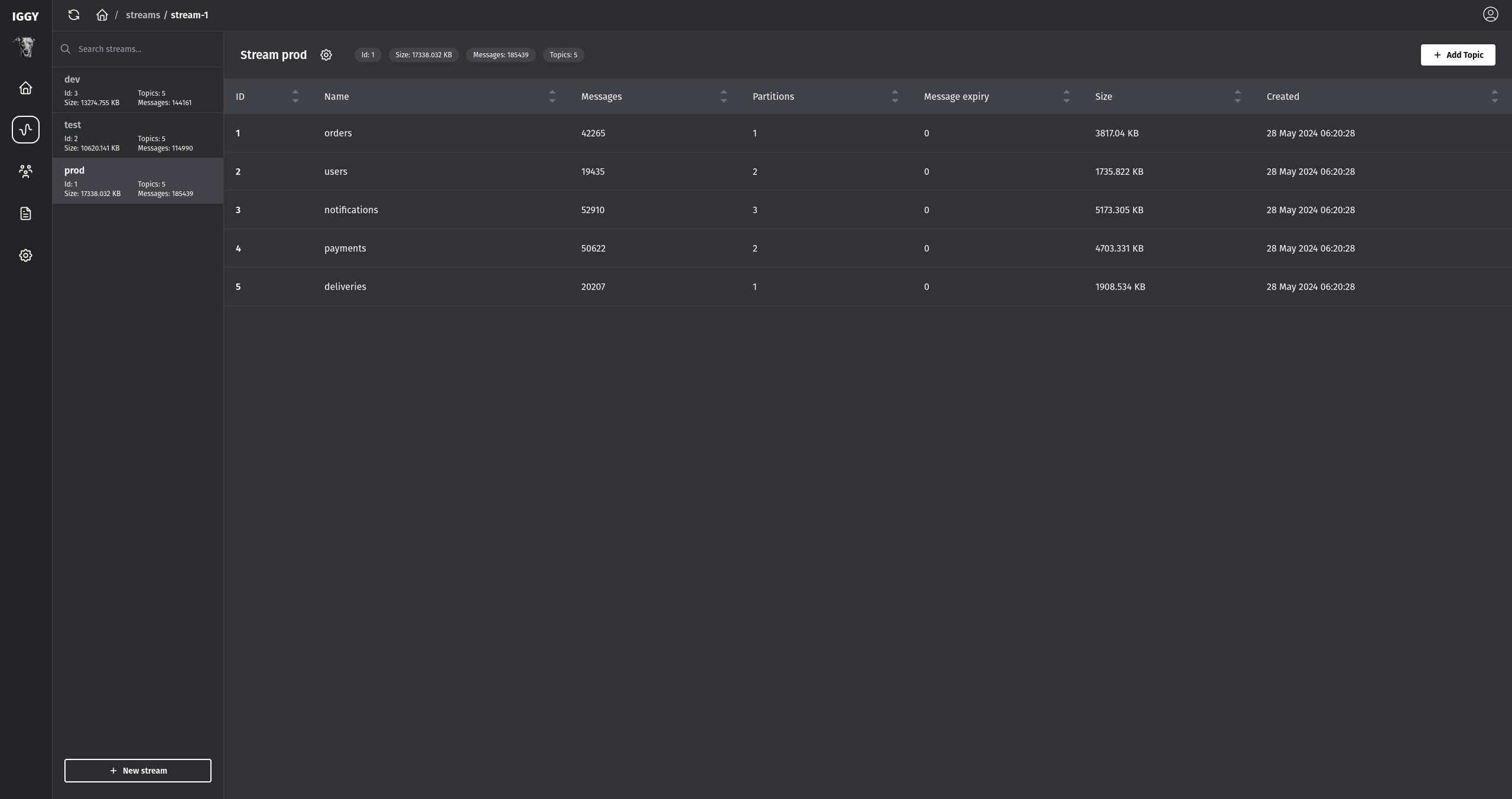
Last but not least, in order to run the benchmarks, we have our own bench available as a part of the core repository — you can easily configure the number of producers, consumers, streams, etc. and get an overview of the possible streaming performance on your machine.
Early adopters
Overall, coding and implementing new features is one side of the story, the other is making an actual use of it. You might have the most sophisticated/performant/reliable (you name it) tooling out there, however, if no one is using it or at least experimenting with it, how could you possibly know whether it's even worth an effort to continue with the further development of the project? Well, I truly wish I had an easy answer how to find users willing to play with your new shiny toy.
In our case, I do believe, that it was a mix of two things — a limited amount of such tooling in the Rust ecosystem (so that the language enthusiasts could to try out something fresh), as well as a much more lightweight and (hopefully) performant message streaming infrastructure than some of the well-established solutions.
I'm fully aware that it's a bold claim, and running the synthetic benchmarks is not a viable proof (e.g. on my 7950X, I was able to hit 3GB/s writes and up to 10 GB/s reads with some additional caching enabled), yet, most of our early adopters were very happy with their results e.g. outnumbering Kafka while utilizing much less memory. For example, Marvin wrote:
20 million msg/sec via tcp is pretty nuts and already blows several commercial systems out of the water.
And he's not the only one who found Iggy.rs to be the right tool for his needs. For example, a few days ago, one of the users on our Discord said that thanks to Iggy he was able to achieve 2ms latency when compared to 300ms with Kafka. Again, just to make it clear, I'm not saying that we're better than X or Y — I'm simply stating that for some specific usages, we might be a better choice than X or Y.
Clustering & replication
One of the most frequent questions we receive is whether we plan to incorporate some sort of data replication feature. Without any doubts, especially when considering the general system resiliency and reliability, being able to spin up a cluster of the particular piece of infrastructure (database/messaging/streaming/logging etc.) is quite often a critical feature.
And yes, we will certainly implement clustering in Iggy — as a matter of fact, we've already built its basic version in the sandbox repository. In order to achieve that, we've decided to (at least for now) stick to the Raft consensus algorithm. However, adding the data replication feature to the core Iggy project will require a new way of storing the server metadata (most likely in a way of event-sourced messages, to play nicely with the replication between the nodes) and one more "tiny" thing regarding the overall I/O.
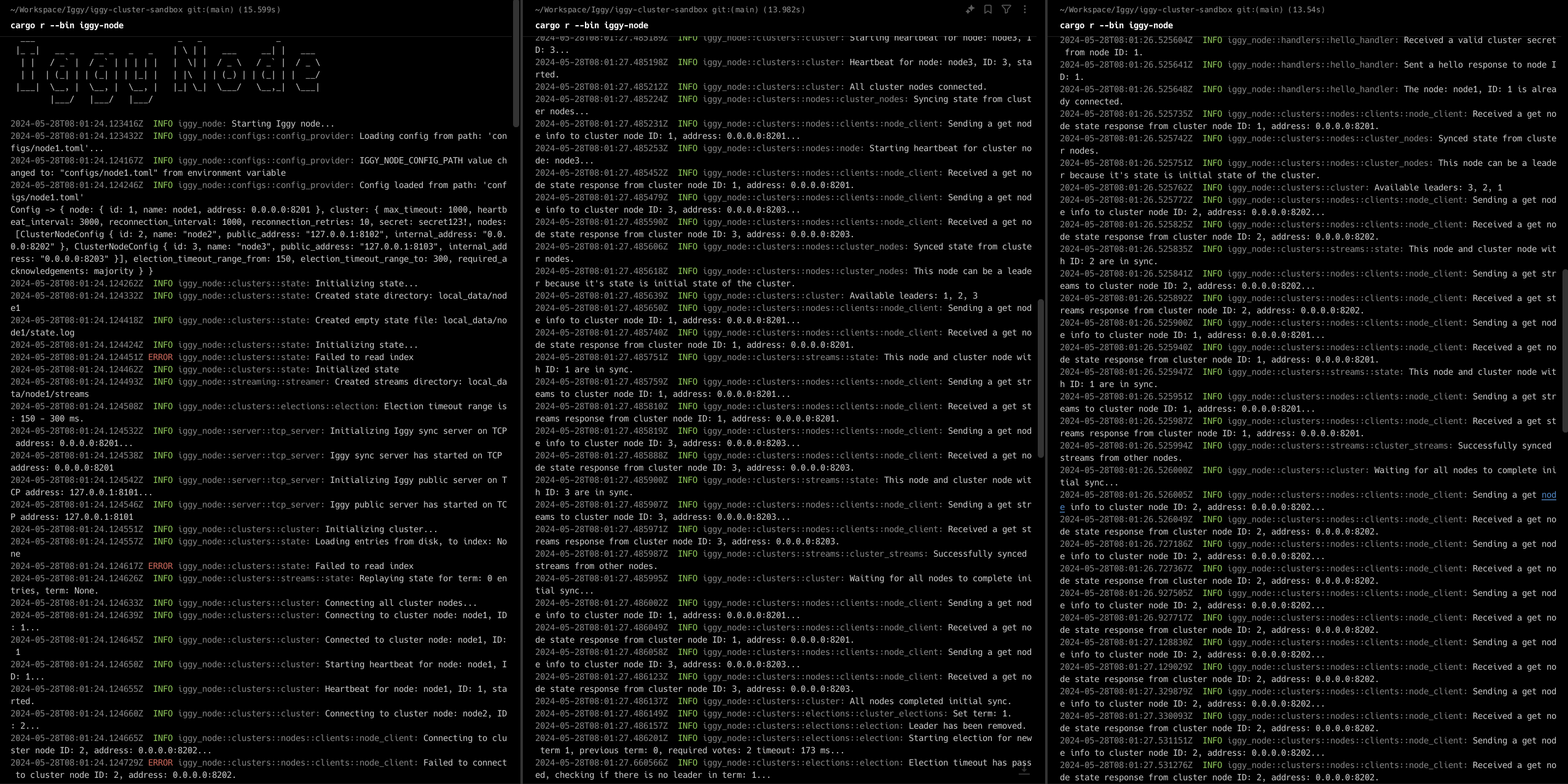
io_uring & thread-per-core + share-nothing
What is a message streaming server, besides some more-or-less complicated logic regarding topics, partitioning, message ordering, consumer groups and a few more features? In its very core, it's mostly I/O (disk + networking) — the more efficient you can make it, the greater it will be. Of course, there's a major difference between throughput and latency, especially when talking about the so-called tail latency (p99 and more). Wouldn't it be great if we could have a very high throughput and very stable/predictable (and low) latency at the same time? This is exactly what we're currently trying to achieve. Originally, we've started with the most popular Tokio runtime, which uses the work-stealing approach, and it's actually quite impressive (based on the benchmarks and the experiences shared by our early adopters).
However, due to the nature of tasks being shared across the different threads, you can't simply avoid lots of context switches and data being shared & synchronized across these threads (therefore even more context switches will occur). While it's probably not an issue for like 90% or maybe even 99% use-cases, there might be some (financial systems and similar), where an unpredictable tail latency is a total no-go.
Certainly, there are already existing solutions dealing with such challenges, such as Aeron, but we do believe, that we can make Iggy something much easier to use — one that can handle the typical workloads, as well as the very demanding ones, without the need of getting a PhD in specific tooling :)
We've decided to experiment with io_uring to maximize the I/O performance (and at the same time vastly reduce the need of context switches), and at the same time utilize thread-per-core architecture, where each thread is pinned to the CPU core, thus keeping the data locally, without the need of sharing it with the other threads (share-nothing). In order to achieve this, we've picked up monoio runtime, and have already managed (as a starting point for future integration) to fully rewrite existing Tokio runtime into monoio on this branch.
And just recently, we've established yet another sandbox repository to tackle the different challenges before deciding on the best solution possible and merging these changes into core Iggy streaming server.
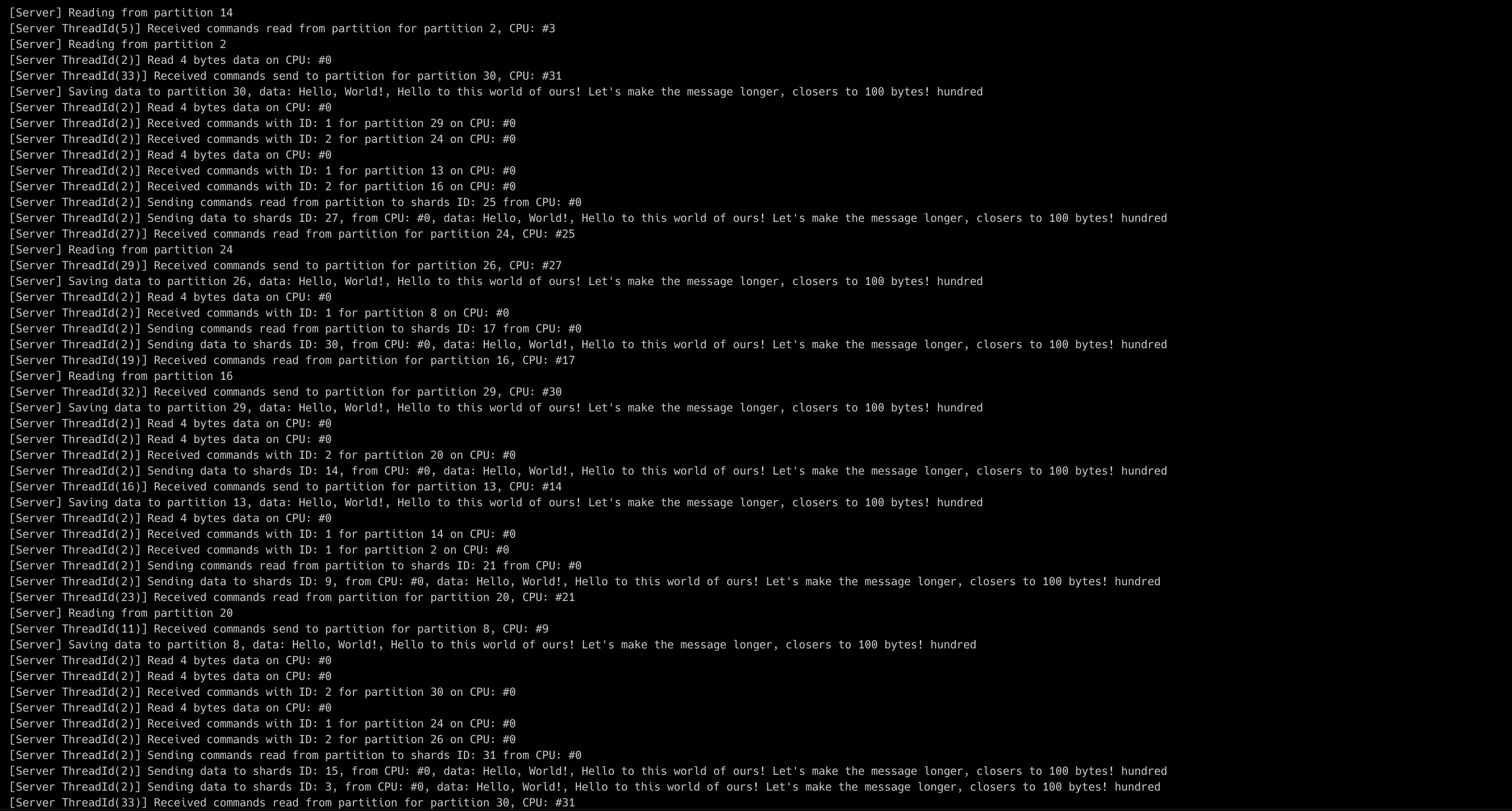
So far, we've got a very simple prototype in place, but there's still lots to be done, especially when thinking of:
- How to evenly split partitions (the unit of data parallelism) between multiple cores?
- How to efficiently rewrite existing server metadata heavily relying on synchronized data with
Arc<>andRwLock<>? - Should we load into memory the same server metadata across all the threads (separately from each other) and notify all of them when something changes?
- Should there be single or multiple threads handling the incoming TCP connections?
- When
Thread #1receives the request, which has to access the partition fromThread #2, should we use an async two-way channel (remember, no explicit locking and data synchronization between the threads) or maybe just send the descriptor using a one-way channel to the second thread to complete the request? - What and when could become a bottleneck in such architecture?
This is just the tip of an iceberg, and we've already started studying some of the existing solutions out there, including Seastar framework. As you can see, this part has to be done before the clustering, as it involves lots of changes not only regarding the disk I/O, but also networking I/O.
Production readiness
Is it ready for production deployment? When you look at the versioning, Rust SDK is at 0.4.* and the server is currently at 0.2.*, which may look like a very long way from v1.0.
As mentioned before, some of our users already experiment with Iggy — and simply because of this, we haven't really introduced any significant breaking changes (except one regarding data compression, which was handled by the provided data migration feature).
We can't guarantee that it will always be like this, but at least for now, we do not see anything that would dramatically impact the existing solution. One of such things could be the redesigned storage, I/O, and clustering feature (as described in the previous paragraph), but even then, we'll do our best to make it as seamless upgrade as possible — and once we achieve that, it means, we're getting very close to the version 1.0.
For the time being, if you're fine with a single-node solution that delivers a really good message streaming performance, give Iggy a try, or at least run the benchmarks to see what are its possibilities and please share your results and thoughts on our Discord — your opinion is really important to us and we respect it no matter what.
It's been a very productive year for our core team (we've been and still are doing this in our free time), and once again, huge thanks to all our supporters and contributors!
We've got the fundamentals right, now it's high time to make Iggy blazingly fast!
