Table of Contents
Technology Radar
Quite recently (a few days ago), Iggy has been listed on Technology Radar by Thoughtworks - a well-known technology consulting company.
If you're not familiar with the Technology Radar, it's essentially an opinionated set (updated twice a year and subscribed by the thousands of developers worldwide) of the tools, platforms, frameworks, techniques etc. which you may want to try out & explore in your IT projects. Everything is split into the different categories, depending on the maturity or popularity of the particular tool.
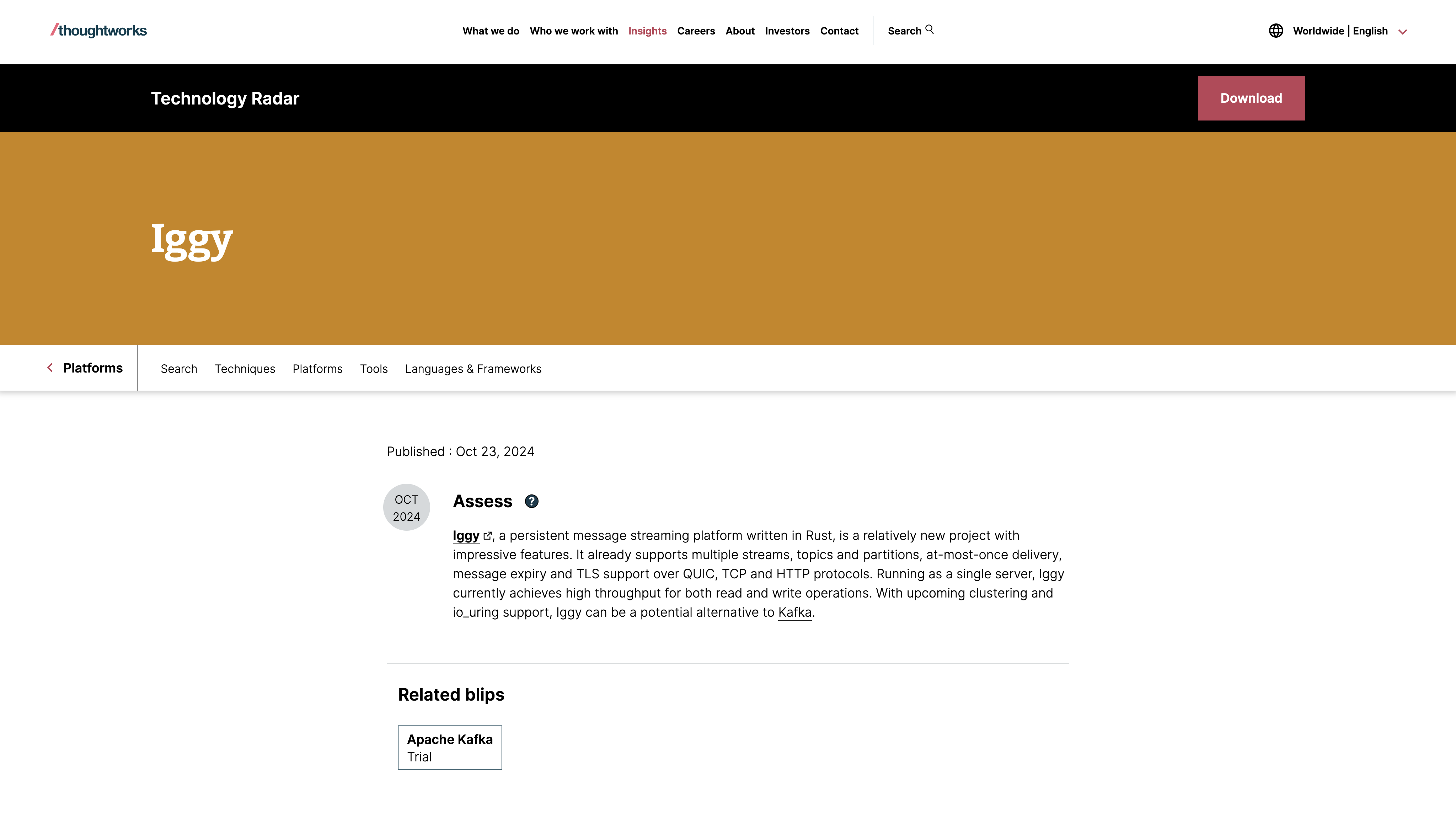
As you can see, we were put right into the assess bucket (next to such renowned solutions such as e.g. FoundationDB) - being the projects which are worth exploring & understanding how they might affect your enterprise. Frankly speaking, we weren't expecting this at all, and from our perspective, it's quite of an accomplishment.
Besides gaining an additional amount of trust & recognition, it has led us to another conclusion - someone out there we don't know yet about (maybe even one of their customers) is using/experimenting with Iggy :)
And if you are (or will be) one of such persons, please hop onto our Discord and share your invaluable feedback with us!
Now, given the recent publication and increased activity within our OSS community building the core streaming server & SDKs in multiple programming languages, it's worth mentioning what are the current goals for Iggy.
Current goals
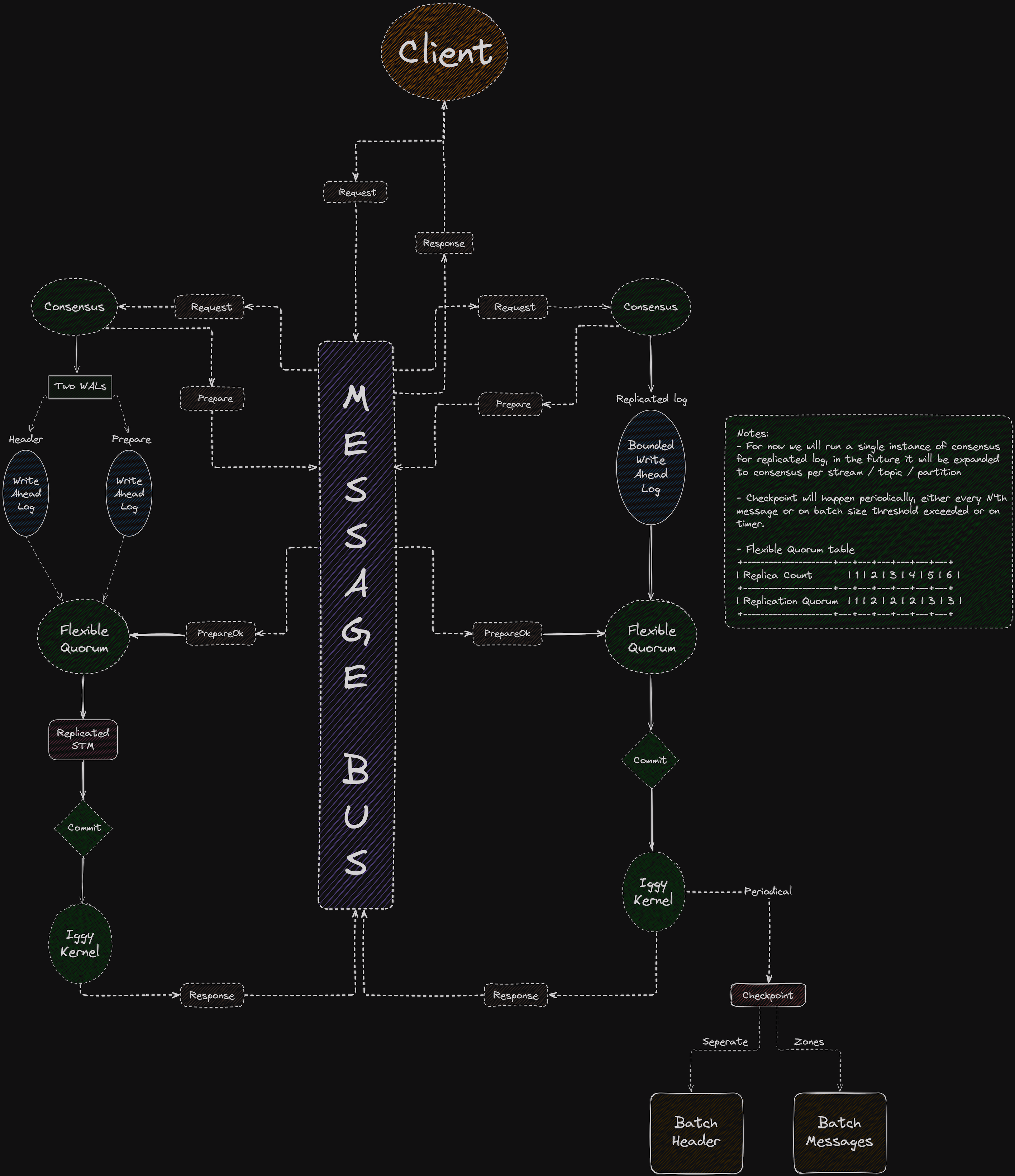
Replication
Without a doubt, being able to run your infrastructure (which processes & stores the data) as a cluster, gives much more confidence and greatly impacts the overall reliability.
We've started experimenting with the replication over half a year ago already by implementing the basic, Raft based consensus algorithm for the simple message streaming server.
At the same time, we were researching the other possible solutions, after we've finally decided to move on with Viewstamped Replication (in its revisited form), which was successfully used by e.g. TigerBeetle.
Long story short - the deterministic leader election, allows us to go for ring topology and chain replication of our data - it's excellent for high throughput, which is very important for us.
Moreover, VSR can be run completely in memory, providing us an opportunity to work independently both on the consensus and the storage and how to link these two together, to form a bulletproof storage fault model.
Below is our very first draft for the initial implementation of VSR.
S3 storage
A few months ago, we did implement an optional archiver for the server state log & streaming data (messages etc.) which supports any S3 compatible storage (just pick up your favorite cloud provider). The configuration is as simple as this example:
[data_maintenance.archiver]
# Enables or disables the archiver process.
enabled = true
# Kind of archiver to use. Available options: "disk", "s3".
kind = "s3"
[data_maintenance.archiver.disk]
# Path for storing the archived data on disk.
path = "local_data/archive"
[data_maintenance.archiver.s3]
# Access key ID for the S3 bucket.
key_id = "123"
# Secret access key for the S3 bucket
key_secret = "secret"
# Name of the S3 bucket.
bucket = "iggy"
# Endpoint of the S3 region.
endpoint = "http://localhost:9000"
# Region of the S3 bucket.
region = "eu-west-1"
# Temporary directory for storing the data before uploading to S3.
tmp_upload_dir = "local_data/s3_tmp"
By making use of S3, you could almost infinitely (and very cheaply) store your data - for the need of additional backups, being compliant with law regulations etc. However, there's one catch - in order to read the data stored with S3, you'd need to download it from the cloud and restart your server. And this is where things will change in the future - we're planning to implement a dedicated S3 storage, for both, writing and reading the data in real-time if needed. You could think of the following analogy to the different kinds of cache storages in your PC.
- L1 - data available directly from the server RAM (super fast writes/reads)
- L2 - data stored on your servers disks (still very, very fast with NVME SSD gen4 or 5)
- L3 - S3 storage, still fast for the typical use-cases which do not require a very stable, microsecond level latencies
Each of these storage layers could be optionally enabled or disabled. You can already decide if and how much memory to use for caching the messages. With S3 tiered storage in place, you could e.g. treat your server's SSD as a sort of ring buffer for keeping the most recent data (easily millions or billions of messages, depending on their size) and only fetch the ones from S3, when you need something very old.
Or, you could just ignore your server's RAM & SSD, and do all the writes and reads directly on S3, and still remain blazingly fast (just like Quickwit).
OpenTelemetry
Speaking of the Quickwit, we've also implemented a support for OpenTelemetry logs & traces for the server. Since our SDK already uses the logging & tracing libraries, we thought that adding such a feature on the server, could help you gain even better, real-time observability into what's happening under the hood.
# OpenTelemetry configuration
[telemetry]
# Enables or disables telemetry.
enabled = false
# Service name for telemetry.
service_name = "iggy"
# OpenTelemetry logs configuration
[telemetry.logs]
# Transport for sending logs. Options: "grpc", "http".
transport = "grpc"
# Endpoint for sending logs.
endpoint = "http://localhost:7281/v1/logs"
# OpenTelemetry traces configuration
[telemetry.traces]
# Transport for sending traces. Options: "grpc", "http".
transport = "grpc"
# Endpoint for sending traces.
endpoint = "http://localhost:7281/v1/traces"
And just like with S3 storage, it's merely a beginning - one of the members on our Discord had already thought of extending this implementation by propagating the trace context (via existing message headers metadata) between the clients & server in order to get full understanding of the distributed systems and its dependencies, which could be further visualized by tools like Zipkin or Jaeger.
Optimizations
Improved messages batching, keeping the indexes & time indexes in a single file, making use of mmap or directIO for the data storage processing, rkyv for zero-copy (de)serialization, keeping open the file descriptors and lots of other minor improvements - all these low hanging fruits (or at least some of them), will hopefully build up to making Iggy even more performant & resource effective than it already is.
To start the Iggy server, you just need to wait for a few milliseconds, and the RAM consumption is within a range ~20 MB, which is already over an order of magnitude lower than when compared to Kafka.
io_uring
This will certainly require to have its own blog post, as there's so much to talk about. We did experiment with Monoio (which, in its basic form without additonal enhancements allowed us to reach over 15 GB/s reads when compared to 10-12 GB/s for Tokio that we currently use), we also might experiment with Glommio, yet, most likely, we might build our own io_uring backend to fully utilize all its features.
Yes, at this point you might call us crazy (io_uring won't happen before we release the first version of the VSR clustering anyway), but if you want to tick all the possible boxes, it's hard to find a generic framework that will meet your demands, especially when mixed altogether with VSR clustering, thread-per-core & shared-nothing design (if will turn out to be suitable), zero-copy deserialization libraries and other things we might even not be aware of yet.
To innovate, one must experiment, and although we do all these things in our spare time, it's been an exciting journey so far (and lots of experience gained in the meantime) for all of our team members building something fresh, from the very ground up, and regardless of the final outcome, we already know it was all worth it :)